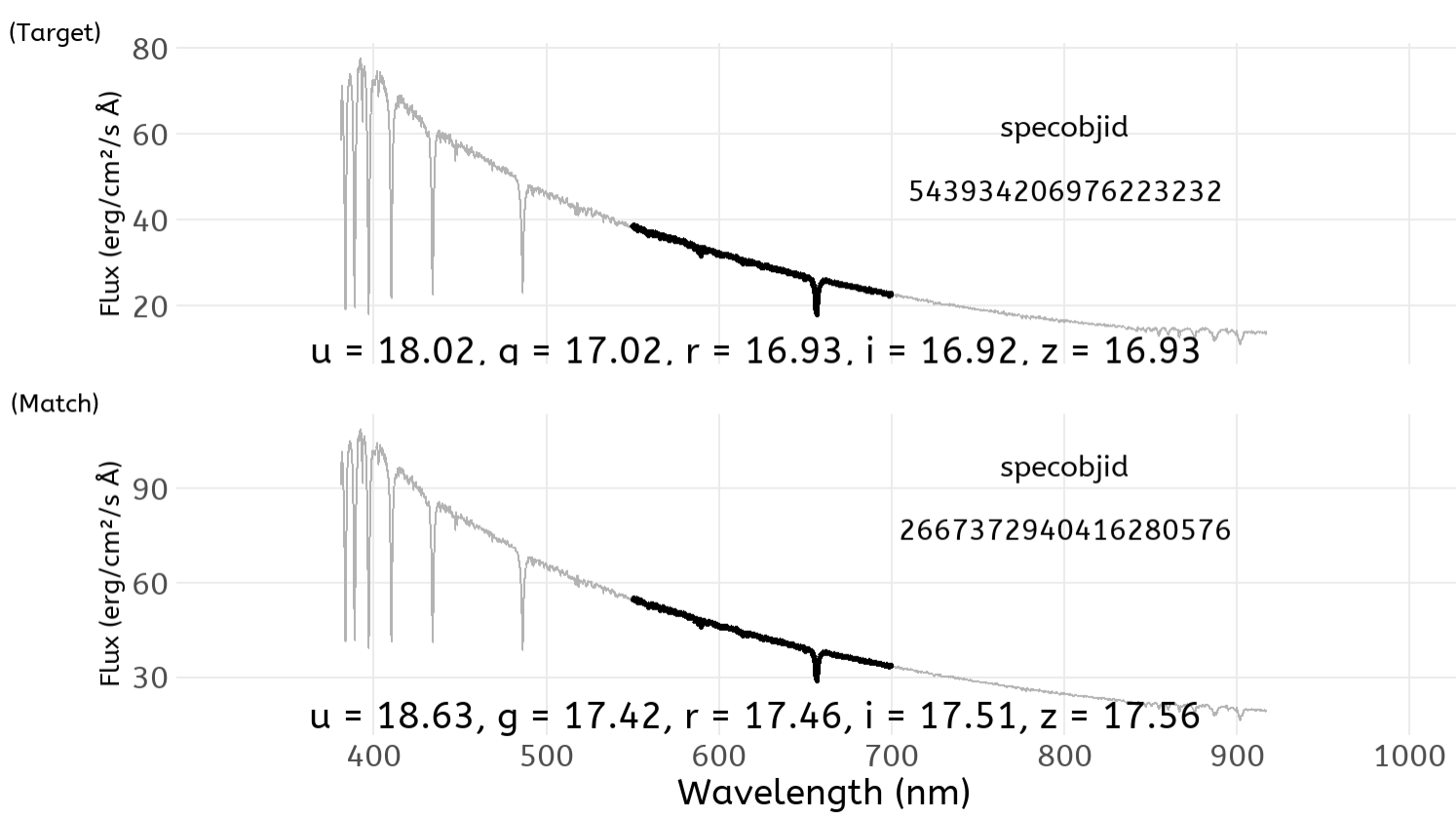
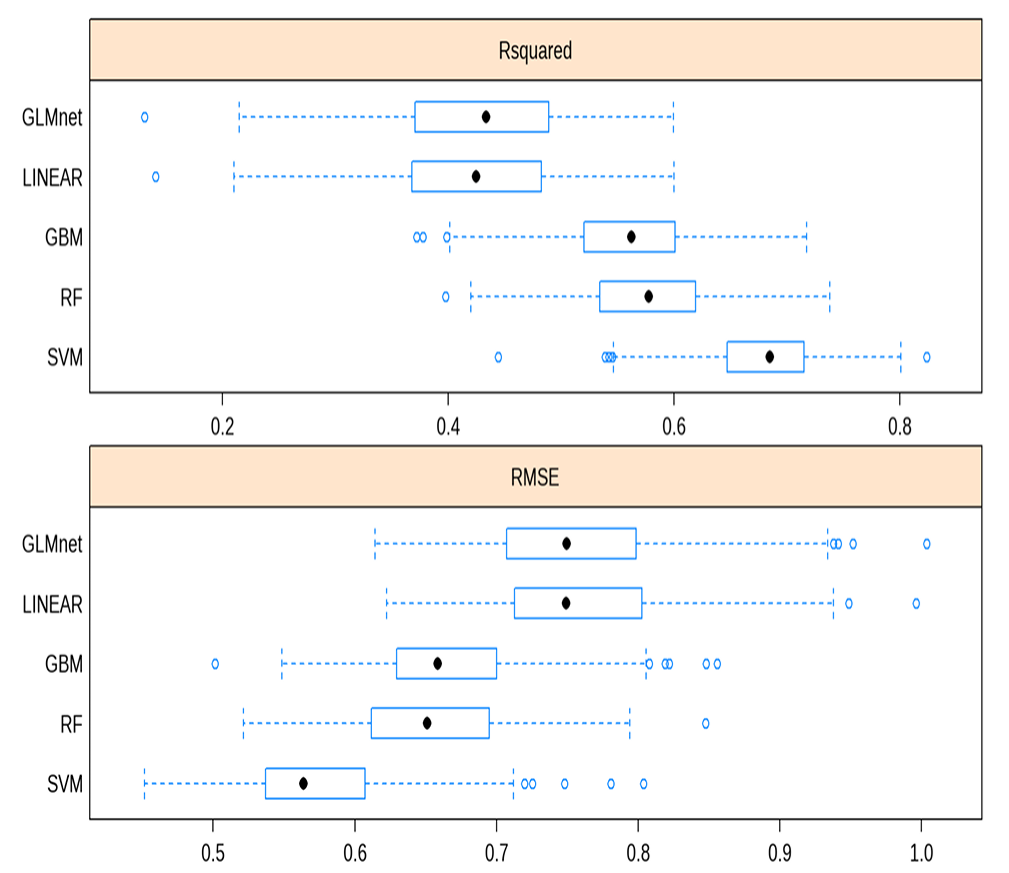
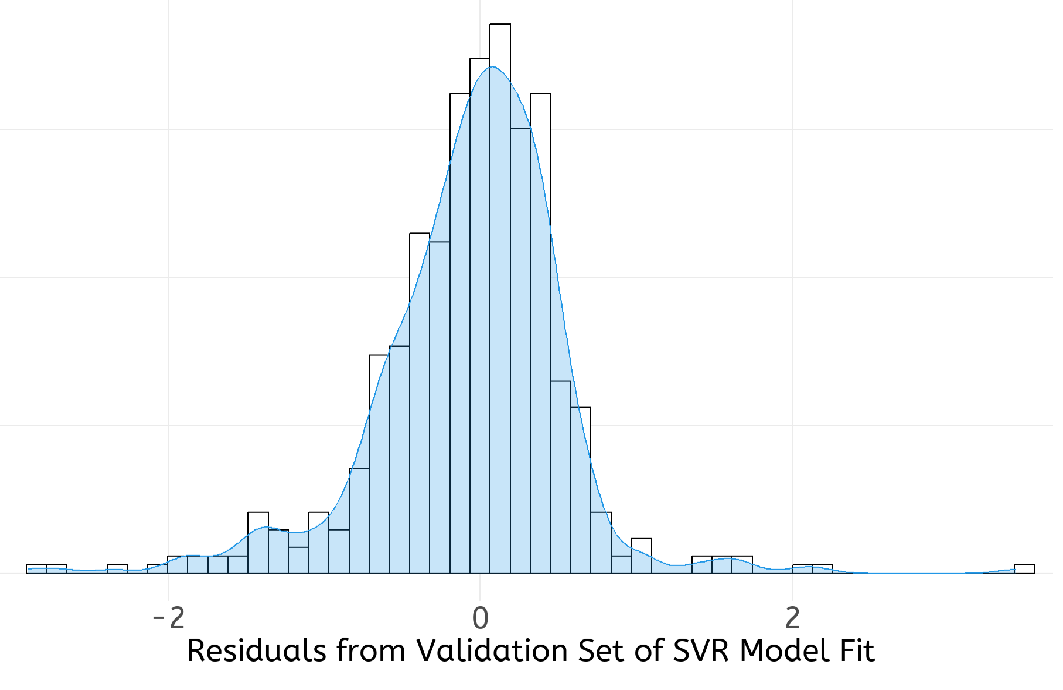
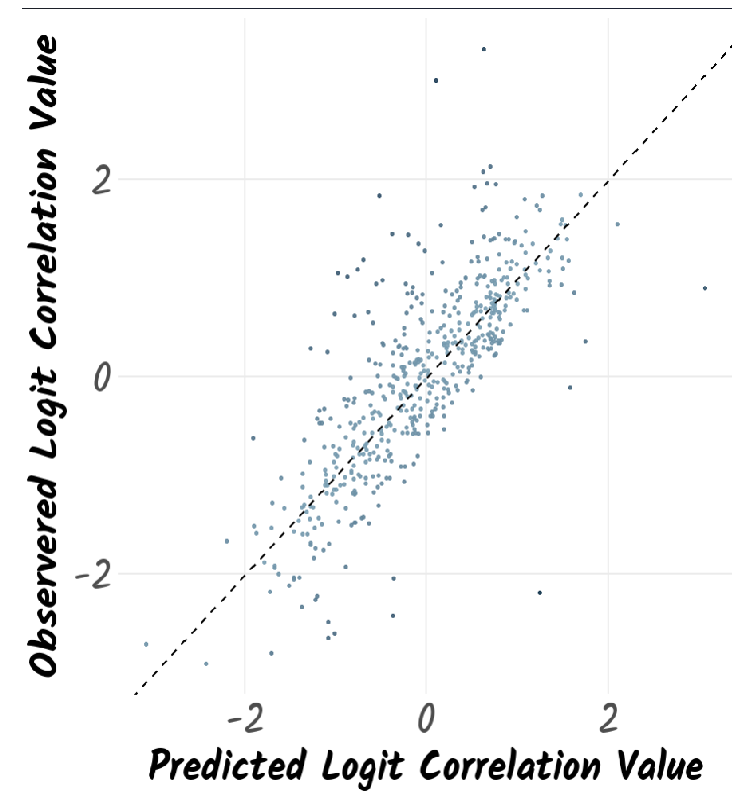
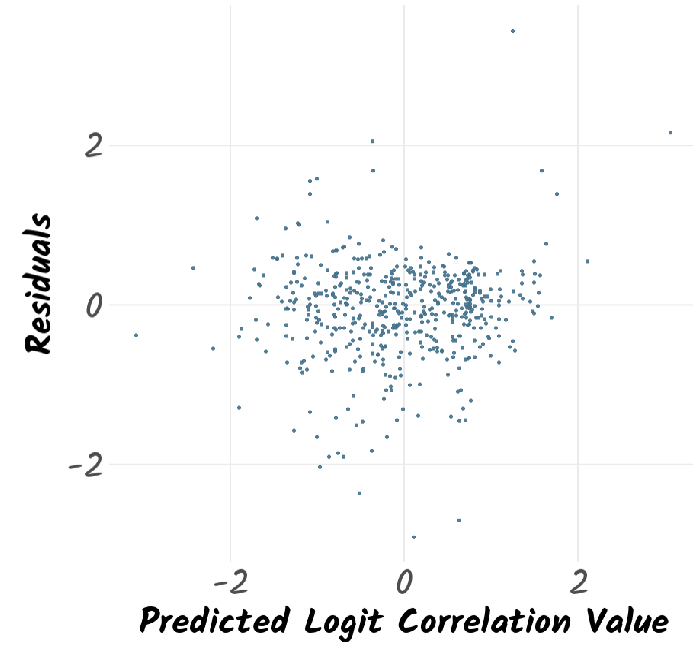
Support Vector Regression follows the general principle of Support Vector Machines, but for regression rather than classification. It fits the data using a hyperplane, a plane in high dimensional space. An extra dimension is added using a kernel that facilitates fitting complex relationships. The hyperparameters Cost and 𝜎 are used to reduce overfitting of the data. The work here used a radial basis kernel function (Karatzoglou et al., 2004). A grid search on the hyperparameters Cost (C) and sigma (𝜎) was undertaken for values 8 < C < 25 and 0.08 < 𝜎 < 0.20. The model was optimised based on the RMSE of the training set. The best tune was obtained for C = 20 and 𝜎 = 0.12.
Random Forests consist of an ensemble of a large number of decision trees (Breiman, 2001). Each tree is built from different subsamples of the training data. In addition, the split at each node is chosen based on a random subset of features which differs at every split. For regression, the mean of the predicted value from every tree is taken to be the overall predicted value. The work here used the ranger fast implementation of random forests (Wright and Ziegler, 2017). The number of trees was set to 500. The Minimum Node Size was set to be 5, the splitting rule was chosen to be variance. The number of variables to possibly split at each node (mtry) was tuned to be 6.
Gradient Boosting uses an iterative series of decision trees where poorly predicted values in the training set are up-weighted in subsequent iterations. Here Friedman’s gradient boosting algorithm (Boehmke and Greenwell, 2019) was used. A grid search on the hyperparameters Number of Boosting Iterations (n.trees), Maximum Tree Depth (interaction.depth), Shrinkage (shrinkage) which corresponds to the Learning Rate, and Minimum Terminal Node Size (n.minobsinnode) was undertaken. The model was optimised based on the RMSE of the training set. The best tune was obtained for n.trees = 100, interaction.depth = 10, n.minobsinnode = 10, and shrinkage = 0.1.
Generalised Linear Model fits generalised linear models by optimising the maximum likelihood (Friedman et al., 2010). It implements regularisation via a hyperparameter 𝛼 that varies from 0 (ridge regression) to 1 (lasso regression). It also optimises a regularisation penalty, 𝜆. The best performing parameters here were 𝛼 = 0.1 and 𝜆 = 6.7×10−4
Linear Model was the simplest model used in this work. It consisted of refining an intercept as well as coefficients for each of the ten features in the model that minimised the RMSE between predicted and observed logit correlations. The linear model used the MASS R package (Venables and Ripley, 2002). There were no tunable parameters.